
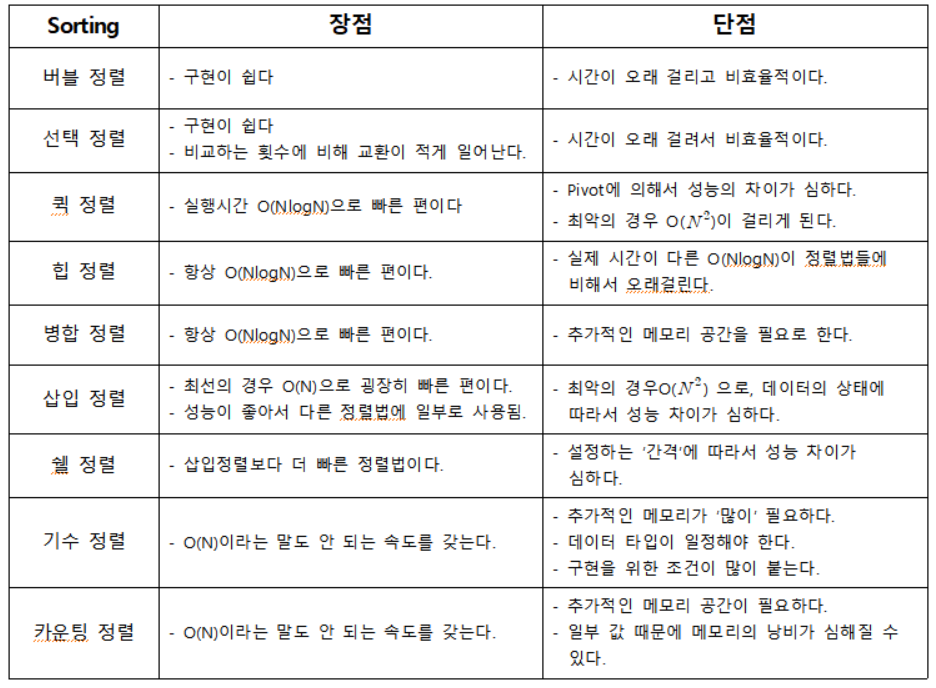
정렬 알고리즘 이란 ?
1. 안정적인 알고리즘 - 값이 같은 원소의 순서가 정렬 후에도 유지.
2. 안정적이지 않는 알고리즘 - 정렬 후에도 원래의 순서가 유지되는 보장이 없다.
1. 내부 정렬 : 정렬할 모든 데이터를 하나의 배열에 저장할 수 있는 경우에 사용하는 알고리즘
2. 외부 정렬 : 정렬할 모든 데이터를 하나의 배열에 저장할 수 없는 경우에 사용하는 알고리즘
정렬 알고리즘의 핵심 : 교환, 선택, 삽입
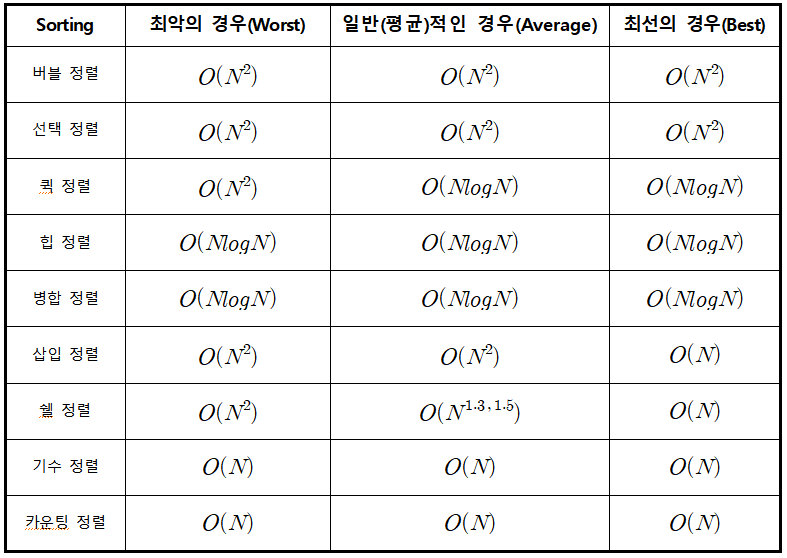
시간복잡도 속도 : O(1) > O(logN) > O(N) > O(NlogN) > O(N2) > O(2N) > O(N!)
1. 버블 정렬
버블 정렬은 이웃한 두 원소를 비교하여 필요에 따라 교환을 반복하는 알고리즘
비교 , 교환하는 과정을 pass 라고 한다.
|
1
2
3
4
5
6
|
def bubble_sort(a)->None:
n=len(a)
for i in range(n-1):
for j in range(n-1,i,-1):
if a[j-1]>a[j]:
a[j-1],a[j]=a[j],a[j-1]
|
cs |
ex) a=8
첫 번째 i for 문에서는 0부터 7까지 (n-1번 반복)
두 번째 j for 문에서는 7부터 i까지 (인덱스 끝부터 인덱스 처음까지 버블 정렬 수행)
-> 비교를 하여 정렬을 수행
- 알고리즘 개선
1. count 변수 사용 (전 반복문에서 버블 정렬이 일어나지 않으면 이미 정렬이 완료된 상태이다. )
|
1
2
3
4
5
6
7
8
9
10
|
def bubble_sort(a :MutableSequence)->None:
n=len(a)
for i in range(n-1):
count=0
for j in range(n-1,i,-1):
if a[j-1]>a[j]:
a[j-1],a[j]=a[j],a[j-1]
count=1
if count==0:
break
|
cs |
2. last 변수 사용 (전 반목문에서 버블정렬을 이룬 곳까지 반복문을 수행한다.)
if 문 대신 while문을 사용하고 j 반복문에서 마지막으로 이루어진 last 값을 k에 넣어 j의 범위를 지정해준다.
|
1
2
3
4
5
6
7
8
9
10
|
def bubble_sort(a :MutableSequence)->None:
n=len(a)
k=0
while k< n-1:
last= n-1
for j in range(n-1,k,-1):
if a[j-1]>a[j]:
a[j-1],a[j]=a[j],a[j-1]
last=j
k=last
|
cs |
3. 칵테일 정렬 (양쪽으로 번갈아 가면서 정렬을 수행한다. )
처음에는 작은 원소를 맨 앞으로, 다음에는 큰 원소를 맨 뒤로 수행한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
def shaker_sort(a :MutableSequence)->None:
left=0
right=len(a)-1
last=right
while left < right:
for j in range(right, left,-1):
if a[j-1] > a[j]:
a[j-1],a[j]=a[j],a[j-1]
last=j
left=last
for i in range(left,right):
if a[i] > a[i+1]:
a[i],a[i+1]=a[i+1],a[i]
last=i
right=last
|
cs |
2. 단순 선택 정렬
가장 작은 원소부터 선택해서 찾은 다음 알맞은 위치로 이동
|
1
2
3
4
5
6
7
8
9
|
def selection_sort(a):
n=len(a)
for i in range(n-1):
min=i
for j in range(i+1,n):
if a[j] < a[min] :
min=j
a[i],a[min]=a[min],a[i]
|
cs |
3. 단순 삽입 정렬 O(n2)
1. 가장 작은 인덱스부터 시작한다.
2. 지정한 인덱스를 temp로 지정한다.
3. 만약 인덱스 번호가 0보다 크거나 앞에 원소가 현재 원소 보다 크면 while문을 실행한다
3.1 앞에 원소가 크면 현재 원소에 앞에 원소를 넣는다.
3.2 j를 감소시킨다. (다음 원소 값을 수행하기 위해)
4. while문을 벗어 났다면 앞에 원소가 없거나 앞에 원소가 현재 원소보다 작다는 것을 의미
4.1 저장했던 temp 변수를 j 인덱스에 넣어준다.
|
1
2
3
4
5
6
7
8
9
|
def insertion_sort(a):
n=len(a)
for i in range(1,n):
j=i
temp=a[i]
while j>0 and a[j-1] > temp:
a[j]=a[j-1]
j-=1
a[j]=temp
|
cs |
4. 이진 삽입 정렬
단순 삽입정렬에 이진 탐색을 수행하여 보다 빠른 시간복잡도를 갖는다.
단순 삽입정렬과 같은 개념이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
def binary_insertion_sort(a):
n = len(a)
for i in range(1, n):
key = a[i]
pl = 0
pr = i - 1
while True: # 정렬된 배열에서 key의 위치를 찾는다.
pc = (pl + pr) // 2
if a[pc] == key:
break
elif a[pc] < key: # ex) [1,3,4] key=3
pl = pc + 1
else:
pr = pc - 1
if pl > pr: # 배열의 원소에 key값이 없으면 무조건 pl>pr이다.
break # ex) [1,3,4] key=2
if pl <= pr: # key값과 배열의 원소 값이 같아 발견했을 시
pd = pc + 1
else: # key값의 위치
pd = pr + 1 # pd=pl 도 된다.
print(f'pl: {pl}, pr: {pr}, pd: {pd}')
for j in range(i, pd, -1):
a[j] = a[j-1]
a[pd] = key
|
cs |
- bisect.insort 함수
a가 이미 정렬된상태를 유지하면서 0~i 사이에 i를 삽입한다.
|
1
2
3
4
5
|
import bisect
def bi(a):
for i in range(1,len(a)):
bisect.insort(a,a.pop(i),0,i)
|
cs |
5. 셸 정렬 O(n 1.25)
셸 정렬은 단순 삽입 정렬의 장점은 살리고 단점을 보완한 알고리즘
(정렬의 횟수는 늘어나지만 원소의 이동횟수가 줄어든다)
1. 정렬한 배열의 원소를 그룹으로 나눠 그룹별로 정렬을 수행
2. 정렬된 그룹을 합치는 작업을 반복 (4칸 떨어진 원소를 정렬하는 방법 4-정렬)
1. h 값은 n//2 로 반복된다. ex) h=8, h=4 , h=2 ,h=1
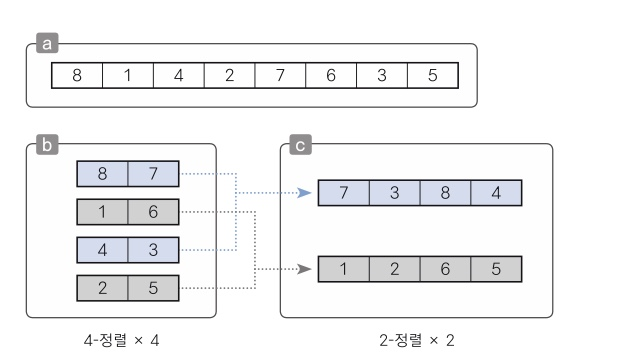
a. h=8 일 경우
b. h=4 일 경우 (2개씩 4개의 그룹이 생김)
c. h=2 일 경우 (4개씩 2개의 그룹이 생김)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def shell_sort_01(a):
size= len(a)
gap=size//2
while gap>0:
for i in range(gap,size):
j=i-gap
tmp=a[i]
while j>=0 and a[j]>tmp:
a[j+gap]=a[j]
j-=gap
a[j+gap]=tmp
gap//=2
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def shell_sort_02(a):
size=len(a)
gap=size//2
while gap>0: # 차이가 0이 될 때까지 반복
for i in range(gap,size): # 집합을 만들기 위한 변수 i
j=i
tmp=a[i] # 임시저장 변수
while j>=0 and a[j-gap] > tmp: # j가 0보다 클때까지 그리고 저장변수가 앞에있는 집합 배열 인덱스보다 작을때
a[j]=a[j-gap] # 앞에있는 집합 배열인덱스에 값을 넣어줌 (삽입정렬)
j-=gap # 집합의 인덱스를 사용하기 위해 gap만큼 빼줌
a[j]=tmp
gap//=2
|
cs |
1. gap= 4, 4부터 8까지 반복한다. (gap=4, (i-gap)으로 교환을 한다. 집합 4개)
2. gap=2 , 2부터 8까지 반복한다. (gap=2, (i-gap)으로 교환을 한다 집합 2개)
j=j-gap 을 통해 탐색을 시작한다.
ex) 1. 집합 [8 1 4 2 7 6 3 5] , i=7 일 경우
2. i=7으로 값은 5이다. tmp=a[i] -> tmp=5
3. while 문 j>=0 and a[j-gap] > tmp ( 7>=0 and 6>5) * 현재 j-gap은 1,3,5,7 인덱스이다. (1,2,6,5)
4. 삽입 정렬 수행...
5. 임시저장 변수 a[j]에 넣기
6. 퀵 정렬
피벗 값을 기준으로 각 그룹을 정렬해서 만든다.
1. x값을 피벗으로 설정 pl과 pr 초기값 설정
2. a[pl]>x , a[pr]<x 로 정렬을 수행
while a[pl] < x , a[pr] >x - x를 기준으로 이미 정렬이 되었기 때문에 넘어간다.
- 1. 피벗 값을 기준으로 정렬하기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def qsort(a):
n=len(a)
pl=0
pr=n-1
x=a[n//2]
while pr>=pl:
while a[pl]<x:pl+=1
while a[pr]>x:pr-=1
if pl<=pr:
a[pl],a[pr]=a[pr],a[pl]
pl+=1
pr-=1
print(a[0:pl]) # 피벗 값을 기준으로 피벗 값 이하의 값들
print(a[pr+1:n]) # 피벗 값 이상의 값들
|
cs |
- 2. 재귀 함수 사용하기
|
1
2
|
if left < pr: qsort(a,left,pr) # pr 이 중간 값이 되고 pr 까지 다시 정렬
if right > pl: qsort(a,pl,right) # pl 이 중간 값이 되고 pl 부터 다시 정렬
|
cs |
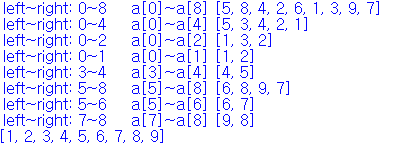
기준을 right와 left로 잡아야한다.
초기 left 값과 right 값은 0~8
처음 while문을 이용하면 pl은 5 pr은 4가 된다.
즉 pl과 pr은 중간 값으로 생각하면 된다.
배열을 반으로 나누었으면 재귀 함수를 이용하여 반복을 수행한다.
if left < pr : qsort(a,left,pr) - 0(처음 값)~중간 값 (pr-1) 까지 다시 반복 수행
if right > pl : qsort(pl,right) - 중간 값 (pl)~ right(끝 값) 까지 다시 반복 수행
즉 pl은 0이 될때까지 pr은 8이 될때까지 반복을 수행하는 것이다.
- 3. 피벗을 선택하기 (효율적이지 않는 값을 선택했을 시 속도가 느려진다)
-> 인덱스 처음 값, 중간 값, 마지막 값을 비교하여 정렬을 수행한다.
| 5 | 2 | 8 | 4 | 2 |
| 2 | 2 | 5 | 4 | 8 |
|
1
2
3
4
5
|
def sort3(a,idx1,idx2,idx3):
if a[idx1] > a[idx2] : a[idx2],a[idx1]=a[idx1],a[idx2]
if a[idx2] > a[idx3] : a[idx2],a[idx3]=a[idx3],a[idx2]
if a[idx1] > a[idx2] : a[idx2],a[idx1]=a[idx1],a[idx2]
|
cs |
- 4. 각 알고리즘을 합친 퀵 정렬 알고리즘
배열이 9보다 작을 경우에는 퀵정렬이 효울적이지 않다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
def sort3(a,idx1,idx2,idx3):
if a[idx1] > a[idx2] : a[idx2],a[idx1]=a[idx1],a[idx2]
if a[idx2] > a[idx3] : a[idx2],a[idx3]=a[idx3],a[idx2]
if a[idx1] > a[idx2] : a[idx2],a[idx1]=a[idx1],a[idx2]
return idx2 def insertion(a,left,right):
for i in range(left+1,right+1):
j=i
temp=a[i]
while j>0 and a[j-1]>temp:
a[j]=a[j-1]
j-=1
a[j]=temp
def qsort(a,left,right):
if right-left<9:
insertion(a,left,right)
else:
pl=left
pr=right
mid=sort3(a,pl,(pr+pl)//2,pr)
x=a[mid]
a[mid],a[pr-1]=a[pr-1],a[mid] # 중간 값을 마지막 값 앞에 둔다.
pl+=1 # 처음값을 정렬을 하였으므로 pl+1
pr-=2 # 마지막 값과 중간 값을 끝에 두었으므로 pr-2
while pr>=pl:
while a[pl]<x:pl+=1
while a[pr]>x:pr-=1
if pl<=pr:
a[pl],a[pr]=a[pr],a[pl]
pl+=1
pr-=1
if pl<right: qsort(a,pl,right)
if pr>left : qsort(a,left,pr)
|
cs |
7. 병합 정렬
배열을 앞부분과 뒷부분의 두 그룹으로 나누어 각각 정렬한 후 병합하는 작업을 반복하는 알고리즘
1. 정렬을 마친 배열의 병합
| 2 | 4 | 6 | 8 | 10 |
| 3 | 6 | 9 | 12 | 15 |
첫 번째 리스트를 a 두번째 리스트를 b 밑 리스트를 c로 가정했을 시
a[0] 과 b[0] 둘중 작은 값을 c[0]에 넣는다.
이후 넣은 리스트 인덱스 값은 1 증가한다. a인덱스 1증가 (a[0]<b[0] -> c[0]=2)
| 2 |
이후 a[1] 과 b[0]을 다시 비교
| 2 | 3 |
... a 인덱스가 a길이만큼 커질 때까지 반복 while a< len(a)
이후 어떤 리스트가 먼저 비워질지 모르니
|
1
2
3
4
5
6
7
8
|
while pa<na:
c[pc]=a[pa]
pa+=1
pc+=1
while pb<nb:
c[pc]=b[pb]
pb+=1
pc+=1
|
cs |
다음 코드를 수행하여 남은 원소를 c에 대입한다.
ex ) a는 비어 있고 b에는 9와 12가 있다.
| 9 | 12 |
-> while pb<len(b): c[pc]=b[pb]
| 2 | 3 | 4 | 6 | 6 | 8 | 9 | 10 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def merge_sorted_list(a,b,c):
pa,pb,pc=0,0,0
na,nb,nc=len(a),len(b),len(c)
while pa < na and pb< nb:
if a[pa]<= b[pb]:
c[pc]=a[pa]
pa+=1
else:
c[pc]=b[pb]
pb+=1
pc+=1
while pa<na:
c[pc]=a[pa]
pa+=1
pc+=1
while pb<nb:
c[pc]=b[pb]
pb+=1
pc+=1
|
cs |
2. 병합 정렬 만들기
1. 재귀 함수를 사용하여 배열을 분리한다.
2. 각 분리된 배열을 정렬을 통해 합친다.
* buff에 a의 앞의 원소를 넣고 a의 뒤의 원소와 비교를 하여 배열 병합을 수행한다.
1. a 배열
| 4 | 1 | 5 | 2 | 0 | 6 |
2. buff 배열 (0~ 중간까지 a 배열을 복사)
| 4 | 1 | 5 |
3. 재귀함수 수행 (분리)
|
1
2
|
_merge_sort(a,left,center)
_merge_sort(a,center+1,right)
|
cs |
를 통해 2로 돌아간다. (3)을 통해 분리된 배열은 정렬이 된다.
4. buff 와 a를 비교
| 1 | 4 | 5 |
| 4 | 1 | 5 | 0 | 2 | 6 |
5. 나머지 buff 원소를 a에 복사
| 0 | 1 | 2 | 4 | 5 | 6 |
- 병합 정렬 알고리즘
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
def merge_sort(a,left,right):
if left<right:
center=(left+right)//2
merge_sort(a,left,center)
merge_sort(a,center+1,right)
p=j=0
i=k=left
while i<=center:
buff[p]=a[i]
p+=1
i+=1
while i<=right and j<p:
if buff[j]<a[i]:
a[k]=buff[j]
j+=1
else:
a[k]=a[i]
i+=1
k+=1
while j<p:
a[k]=buff[j]
j+=1
k+=1
|
cs |
buff는 항상 새로운 값을 넣어주는 공간이라고 생각을 하자
a는 while문 마다 항상 left 값을 넣어주는 공간이라고 생각을 하자
카운팅(도수) 정렬
원소 대소관계를 판단하지 않고 빠르게 정렬하는 알고리즘
arr 배열이 주어짐, f 배열은 arr의 가장 큰 수만큼 주어짐 f=[None]*max(arr)+1
1. 1단계 도수 분보표 만들기
|
1
2
|
for i in range(n):
f[a[i]]+=1
|
cs |
* 도수 분보표란 자료를 몇 개의 등급으로 나누고 각 등급에 속하는 도수를 조사하여 나타낸 표
f배열은 arr 배열의 도수 분보표이다.
0~max(arr) 까지 설정한 f배열에 각각의 수가 들어가있다.
| arr[0] | arr1] | arr[2] | arr[3] | arr[4] | arr[5] |
| 8 | 1 | 5 | 2 | 0 | 3 |
| f[0] | f[1] | f[2] | f[3] | f_[4] | f[5] | f[6] | f[7] | f[8] |
| 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 |
2. 2단계 누적 도수 분보표 만들기
|
1
2
|
for i in range(1,max+1):
f[i]+=f[i-1]
|
cs |
* 누적 도수 분보표란 두번째 원소 값부터 해당 원소 값 까지 몇 명의 인원이 있는지 나타낸 표
| f[0] | f[1] | f[2] | f[3] | f[4] | f[5] | f[6] | f[7] | f[8] |
| 1 | 2 | 3 | 4 | 4 | 5 | 5 | 5 | 6 |
즉 index[3]은 자신을 포함한 4명의 수가 있음을 의미
3. 3단계 작업용 배열 만들기 (임시 배열 b) - 뒤 부터 스캔해야 키 값의 순서 관계가 일정하다.
|
1
2
3
|
for i in range(n-1,-1,-1):
f[a[i]]-=1
b[f[a[i]]]=a[i]
|
cs |
- arr배열
| arr[0] | arr[1] | arr[2] | arr[3] | ar[4] | arr[5] |
| 8 | 1 | 5 | 2 | 0 | 3 |
- f배열
| f[0] | f[1] | f[2] | f[3] | f[4] | f5] | f[6] | f7] | f[8] |
| 1 | 2 | 3 | 4 | 4 | 5 | 5 | 5 | 6 |
- b배열 arr_index[5]~ arr_index[0]
| b[f[arr[4]]-1] | b[f[arr[1]]-1] | b[f[arr[3]]-1] | b[f[arr[5]]-1] | b[f[arr[2]]-1] | b[f[arr[0]]-1] |
| arr[4]=0 | arr[1]=1 | arr[3]=2 | arr[5]=3 | arr[2]=5 | arr[0]=8 |
f 배열의 원소 값은 해당 인덱스~ 앞까지의 인원 수다.
누적 분포표를 사용하는 이유는 같은 원소를 중복으로 처리하지 않기 위함이다.
그러므로 i가 주어졌을 때 b의 인덱스[f의 원소 값[arr의 원소 값]-1]에 arr 원소 값을 넣어주면 된다.
- 1,2,3,4 단계를 합친 카운팅 알고리즘 1
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
def counting_sort(a,max):
n=len(a)
f=[0]*(max+1)
b=[0]*n
for i in range(n):
f[a[i]]+=1
for i in range(1,max+1):
f[i]+=f[i-1]
for i in range(n-1,-1,-1):
f[a[i]]-=1
b[f[a[i]]]=a[i]
for i in range(n):
a[i]=b[i]
|
cs |
- 카운팅 알고리즘 2
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def counting_sort(arr):
n=len(arr)
m=max(arr)
f=[0]*(m+1)
count=0
for i in range(n):
f[arr[i]]+=1
for i in range(m+1):
if f[i]!=0:
for j in range(f[i]):
arr[count]=i
count+=1
|
cs |
'Python > 자료구조 내용 정리' 카테고리의 다른 글
| 자료구조 7장 - 문자열 검색 (0) | 2021.08.26 |
|---|---|
| 자료구조 5장 - 재귀 알고리즘 (0) | 2021.08.09 |
| 자료구조 4장- 스택과 큐 (0) | 2021.08.02 |
| 자료구조 - 3장 검색 알고리즘 (0) | 2021.07.29 |
| 자료구조 - 2장 기본 자료구조와 배열 (0) | 2021.07.27 |